Out-of-Distribution Detection
Blog
April 20, 2026Author: Anju Chhetri
In a now-famous study, expert radiologists were asked to scan CT images of lungs for nodules. Hidden in one of those scans was something no one expected: a gorilla, 48 times the size of the average nodule. However, interestingly more than half the radiologists never noticed it. Their attention was so finely tuned to detecting tumors that they overlooked an unexpected and obvious anomaly. This phenomenon is known as inattentional blindness, where focused expertise can paradoxically limit perception [1].
While this finding is surprising, its implications extend far beyond human cognition. It offers a powerful analogy for understanding a critical challenge in machine learning. Consider a model trained to detect malignant cancer cells. It performs well when the input data resembles what it has seen during training. But what happens when it encounters a completely new disease, something outside its learned distribution? This scenario is known as out-of-distribution data, where the statistical properties differ from the training set.
In such cases, the model does not recognize its own uncertainty. Instead, it forcefully maps the unfamiliar input to one of its known categories. The result can be a confident but incorrect prediction, potentially leading to dangerous misdiagnoses. This limitation arises because most machine learning systems operate under what is called a closed-world assumption. They assume that every input belongs to one of the predefined classes.
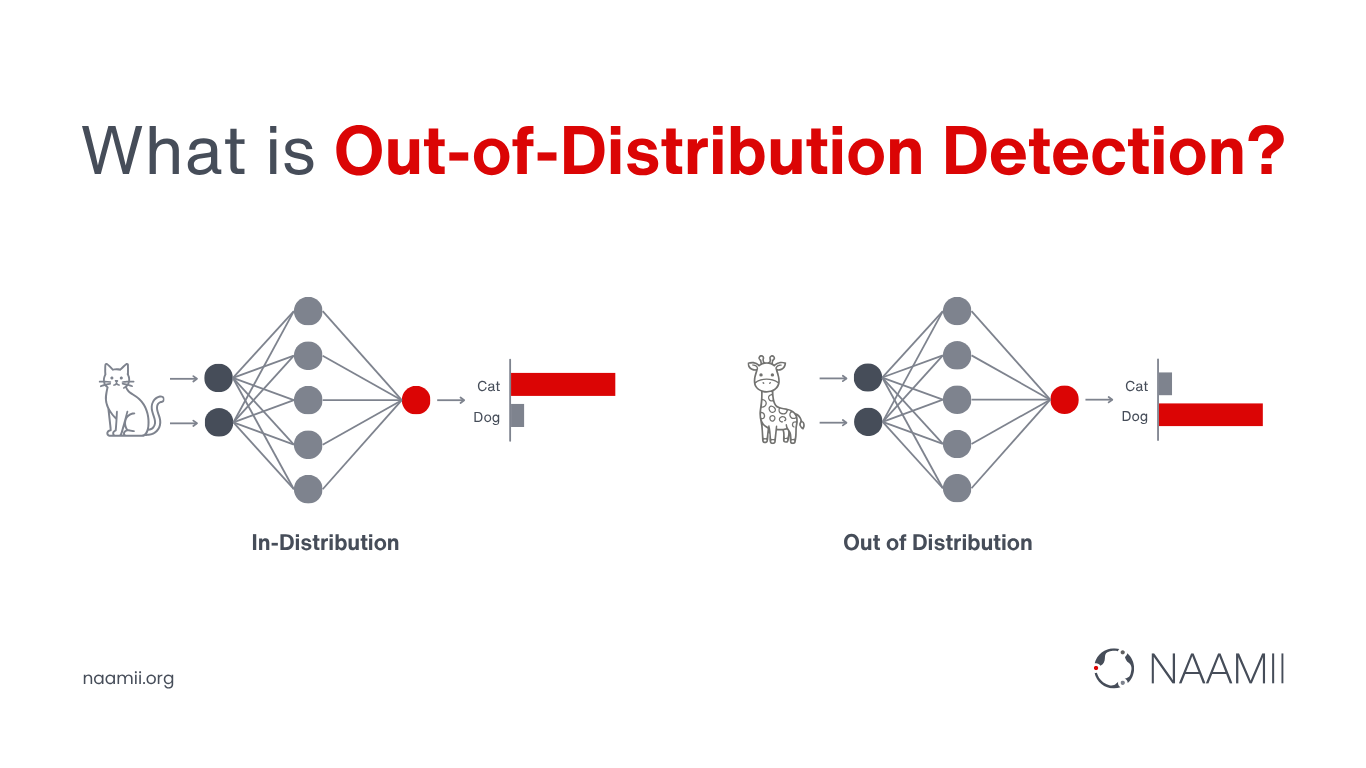
[2]
This challenge is not limited to healthcare. In domains like self-driving cars, encountering unexpected objects or rare environmental conditions can lead to similarly flawed decisions. A plastic bag drifting across the road or an unusual vehicle shape may not fit neatly into the model’s learned categories, yet the system must still respond.
To address this, researchers focus on out-of-distribution detection. The goal is to identify when an input does not belong to the training distribution and flag it instead of forcing a classification. But this raises a key question. If a model is trained only to assign inputs to known classes, how can it recognize something unfamiliar?
One approach is to look beyond final predictions. Instead of relying solely on class labels, we can analyze intermediate signals within the model. These include internal representations, logits, and probability scores. Patterns in these signals can help distinguish familiar inputs from anomalous ones, sometimes using a combination of multiple indicators [3,4,5].
But OOD detection alone isn't enough. As models grow more complex, a deeper question emerges: how do we understand and trust the decisions they make? This demands collaboration beyond machine learning robustness, drawing in interpretability research and explainable AI to make model behavior transparent, not just accurate.
[1] Drew, Trafton, Melissa L-H. Võ, and Jeremy M. Wolfe. "The invisible gorilla strikes again: sustained inattentional blindness in expert observers." Psychological science 24.9 (2013): 1848-1853.
[2] Hou, Mun. “Detecting Out-of-Distribution Samples with kNN | Mun Hou’s Blog.” Detecting Out-of-Distribution Samples with kNN , 2022, blog.munhou.com/2022/12/01/Detecting Out-of-Distribution Samples with Knn/.
[3] Wang, Haoqi, et al. "Vim: Out-of-distribution with virtual-logit matching." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
[4] Hendrycks, Dan, and Kevin Gimpel. "A baseline for detecting misclassified and out-of-distribution examples in neural networks." arXiv preprint arXiv:1610.02136 (2016).
[5] Lee, Kimin, et al. "A simple unified framework for detecting out-of-distribution samples and adversarial attacks." Advances in neural information processing systems 31 (2018).